While most embodied robots today are still focused on basic locomotion tasks—such as walking and running—PsiBot has taken a bold leap forward by tackling long-horizon, complex tasks in open environments, including something as intricate and human-centric as playing Mahjong.
Mahjong, a strategic board game of probabilistic reasoning and interaction, poses a multi-dimensional challenge for robotic intelligence. First, the robot must understand the rules of Mahjong and ensure all actions comply with game logic. Second, it must dynamically generate strategies based on hand state, game progression, and opponents’ behavior—deciding whether to play, meld (chi/peng/gang), or discard tiles. This requires intensive human-robot and robot-robot interaction.
Finally, the physical execution demands millimeter-level precision to complete actions such as drawing tiles, discarding, and arranging them accurately on the table. Altogether, this task places unprecedented demands on a robot’s long-horizon task planning, dexterous manipulation, and real-time adaptability—marking a major milestone in the evolution of truly general-purpose embodied intelligence.
Finally, the physical execution demands millimeter-level precision to complete actions such as drawing tiles, discarding, and arranging them accurately on the table. Altogether, this task places unprecedented demands on a robot’s long-horizon task planning, dexterous manipulation, and real-time adaptability—marking a major milestone in the evolution of truly general-purpose embodied intelligence.

Robotic manipulation capabilities can be categorized into three levels:
L1|Object-level generalization (Pick & Place): The robot can perform basic grasp-and-place tasks but lacks the ability for complex operations and reasoning.
L2|Human-like manipulation: The robot is capable of executing advanced grasps such as medium wrap, precision disk, lateral pinch, tripod, lateral tripod, and power sphere. However, it lacks a cognitive decision-making chain and cannot process complex multimodal instructions.
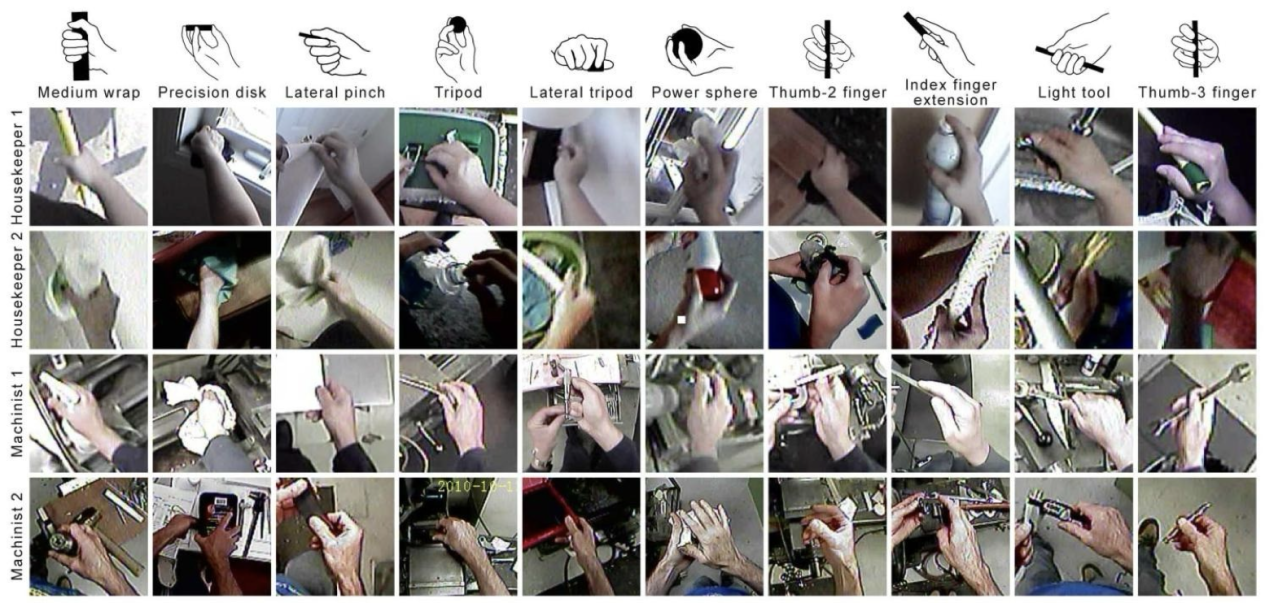
L3|Autonomous reasoning under the Chain of Action Thought (CoAT) framework: The robot can independently perform reasoning and decision-making in open environments, executing long-horizon, complex tasks.
Only robots that reach the L3 level, with long-horizon CoAT-based dexterous manipulation, can genuinely understand the world and transfer learned knowledge to new environments for real-world deployment. A quintessential example of an L3 challenge is the traditional Chinese game of Mahjong—and PsiBot, with its hierarchical end-to-end VLA + reinforcement learning architecture Psi-R1, has delivered a compelling answer.
Using Mahjong as a demonstration setting, Psi R1 showcases the robot’s ability to autonomously complete long-duration dexterous tasks in open environments, maintaining over 30 minutes of continuous CoAT reasoning. It also validates three-fold interaction complexity: human-robot interaction, robot-robot interaction, and robot-environment interaction. The result illustrates the model’s powerful VLA-level reasoning and RL-driven superhuman performance in both thought and execution.
This breakthrough marks a pivotal transition for embodied intelligence—from isolated action execution to closing the loop between perception, reasoning, and action in the complex physical world. It lays a viable technical foundation for the real-world commercialization of embodied AI systems.
Unpacking Core Capabilities Through the Mahjong Demo Video
In the Mahjong video, PsiBot’s R1 model demonstrates a full spectrum of capabilities—from “slow brain” to “fast brain”—showcasing both cognitive reasoning and physical finesse.
“I can flip tiles too” — Flipping Mahjong tiles is a deceptively delicate task that even novice human players often struggle to execute consistently. PsiBot’s dexterous hand, powered by R1, successfully overcomes the challenge of tactile–visual modality alignment, achieving 100% accuracy in flipping tiles upright. This reflects human-level dexterity, highlighting the model’s ability to integrate perception and action at millimeter-level precision in real-world scenarios.

“I can meld too” — The robot is able to observe tiles played by other players and construct a real-time game state machine, enabling it to autonomously form strategic chains for actions like Pung and Kong.

“I’m the best at tile counting” — In embodied agent tasks, long-horizon planning is one of the most challenging capabilities to achieve. PsiBot’s robot not only remembers every tile played by all participants, but also dynamically plans its next move based on the evolving game state. This level of strategic foresight is reminiscent of AlphaGo, reflecting the power of reinforcement learning when combined with PsiBot’s VLA architecture. It enables the embodied agent to perform real-time probabilistic reasoning, memory-based planning, and action execution—a milestone in bringing game-level intelligence into physical reality.

“My teammate’s got my back” — Two robots cooperate seamlessly to demonstrate multi-agent collaborative intelligence. Beyond just information sharing and “seeing each other’s tiles,” they also physically coordinate actions, such as passing tiles between each other. This showcases not only multi-agent perception and communication, but also coordinated manipulation—a breakthrough in embodied systems where multiple agents act as a unified intelligence in dynamic, real-world environments.

At its founding in 2024, PsiBot was the first in the industry to propose a hierarchical end-to-end fast/slow brain architecture, which has since become an industry consensus. This architecture is inspired by cognitive science—dividing intelligence into:
· S1 (Fast Brain): unconscious, intuitive, motor control, rapid response
· S2 (Slow Brain): reasoning, planning, deliberate thinking, conscious depth
This approach has since been echoed across leading players:
· Physical Intelligence (PI) evolved from the end-to-end architecture Pi 0 to the hierarchical Hi Robot.
· Figure AI introduced its hierarchical HELIX architecture in March 2024.
· Google released Gemini Robotics at the end of March.
· NVIDIA followed in April with GR00T N1—all adopting hierarchical structures.
· S1 (Fast Brain): unconscious, intuitive, motor control, rapid response
· S2 (Slow Brain): reasoning, planning, deliberate thinking, conscious depth
This approach has since been echoed across leading players:
· Physical Intelligence (PI) evolved from the end-to-end architecture Pi 0 to the hierarchical Hi Robot.
· Figure AI introduced its hierarchical HELIX architecture in March 2024.
· Google released Gemini Robotics at the end of March.
· NVIDIA followed in April with GR00T N1—all adopting hierarchical structures.
However, as noted by Deiter Fox—Senior Director of Robotics at NVIDIA and Professor at the University of Washington—there are still two core unresolved challenges in implementing fast/slow brain architectures:
· How to align modalities between the fast and slow brain, ensuring smooth coordination between high-level planning and low-level execution.
· How to overcome the limitations of imitation learning and effectively train agents with a rich, diverse skill set.
PsiBot’s Psi-R1 fast/slow brain architecture achieves a major breakthrough in modality alignment and unlocks the embodied “Aha Moment” through the integration of reinforcement learning.
Unlike Pi, Figure, and other VLA models that follow a “unidirectional action decision” mechanism—limited to vision-language-level CoT (Chain of Thought) reasoning—PsiBot’s R1 model introduces a groundbreaking advancement: the Slow Brain (S2) receives not only language and visual inputs, but also action tokens via an Action Tokenizer, enabling the first fully closed-loop VLA system that supports action perception, environment feedback, and dynamic decision-making.
This architecture gives rise to a true Chain of Action Thought (CoAT)—a multimodal reasoning chain across vision, language, and action that enables robots to not just think and see, but also act and adapt in real time.
This architecture gives rise to a true Chain of Action Thought (CoAT)—a multimodal reasoning chain across vision, language, and action that enables robots to not just think and see, but also act and adapt in real time.
The Fast Brain (S1) focuses on execution and supports a wide range of dexterous operations, including:
· Object Mask-based Grasping: Grasping partially occluded or cluttered objects
· Trajectory-Constrained Manipulation: Tasks like pulling zippers or threading cables
· Tool-using Skills Generalization: Using tools such as scanners or drills across different settings
· Raw Actions Stream Execution: High-speed, reactive tasks like catching or throwing objects
These capabilities are supported by PsiBot’s reinforcement learning algorithms, which provide high adaptability and robustness across these complex action classes.
· Object Mask-based Grasping: Grasping partially occluded or cluttered objects
· Trajectory-Constrained Manipulation: Tasks like pulling zippers or threading cables
· Tool-using Skills Generalization: Using tools such as scanners or drills across different settings
· Raw Actions Stream Execution: High-speed, reactive tasks like catching or throwing objects
These capabilities are supported by PsiBot’s reinforcement learning algorithms, which provide high adaptability and robustness across these complex action classes.
The Slow Brain (S2) focuses on reasoning and planning. Actions executed by S1 are tokenized and fed back into S2, where they are fused with visual and language modalities. Based on a causal autoregressive Vision-Language Model (VLM) architecture, S2 performs multi-modal reasoning and task decomposition, enabling high-level decision-making that incorporates prior actions and environmental state.
The Slow Brain (S2) focuses on reasoning and planning. Actions executed by S1 are tokenized and fed back into S2, where they are fused with visual and language modalities. Based on a causal autoregressive Vision-Language Model (VLM) architecture, S2 performs multi-modal reasoning and task decomposition, enabling high-level decision-making that incorporates prior actions and environmental state.
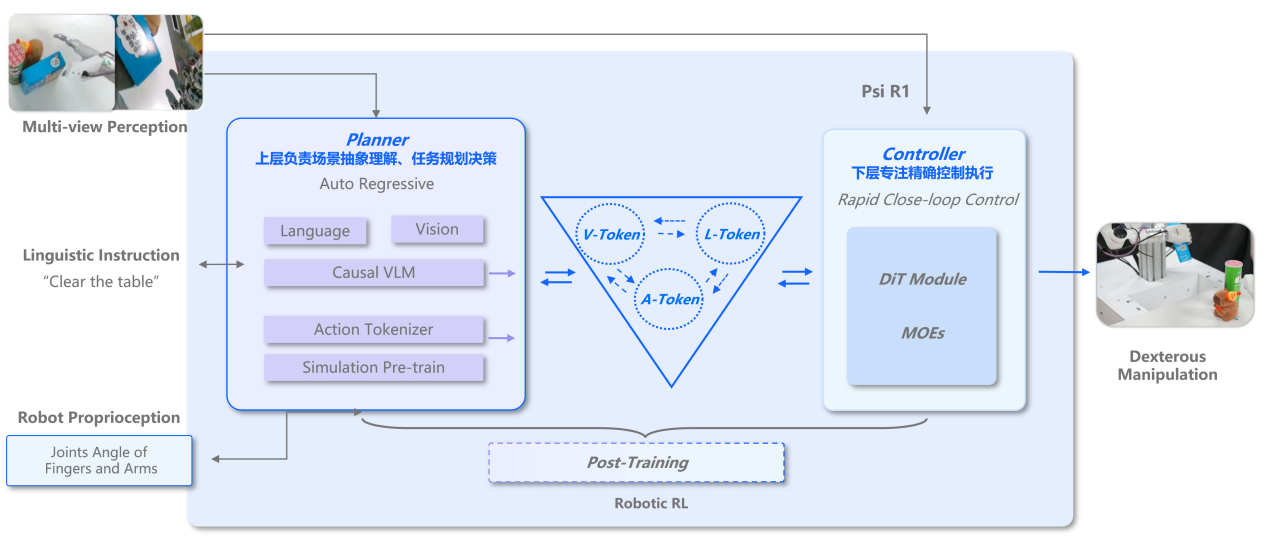
The PsiBot R1 model has become the first to successfully validate VLA Test-Time Scaling.
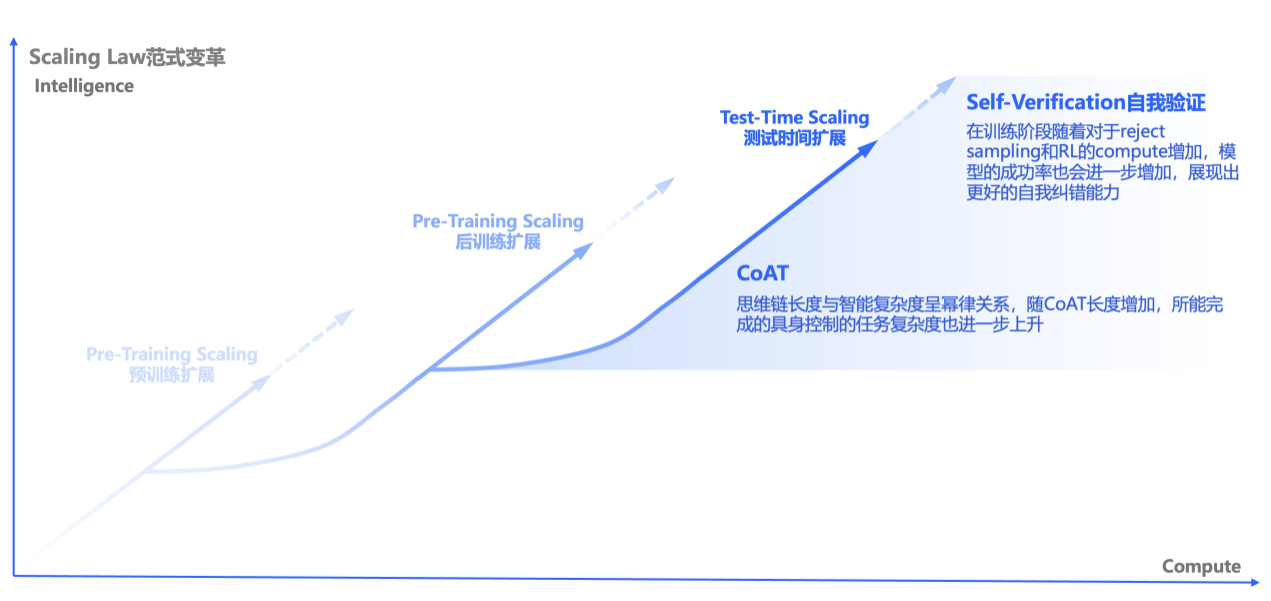
Under an unchanged model architecture, the reinforcement learning (RL) framework enables the model to autonomously simulate, explore, and autonomously solve complex problems—giving rise to a Chain of Action Thought (CoAT) that supports self-verification and reflection within long-horizon tasks.
Self-verification:
As the training progresses—with increased computation from reject sampling and RL fine-tuning—the model’s success rate continues to rise, reflecting enhanced self-correction capabilities. This shows that the agent is not just learning to act, but learning to evaluate and refine its own decision-making process in real time.
As the training progresses—with increased computation from reject sampling and RL fine-tuning—the model’s success rate continues to rise, reflecting enhanced self-correction capabilities. This shows that the agent is not just learning to act, but learning to evaluate and refine its own decision-making process in real time.
CoAT:
The length of the reasoning-action chain follows a power-law relationship with the complexity of intelligence. As the CoAT depth increases, the embodied agent becomes capable of handling increasingly sophisticated control tasks—from simple pick-and-place to tool use, collaboration, and strategic gameplay.
The length of the reasoning-action chain follows a power-law relationship with the complexity of intelligence. As the CoAT depth increases, the embodied agent becomes capable of handling increasingly sophisticated control tasks—from simple pick-and-place to tool use, collaboration, and strategic gameplay.
Reinforcement learning (RL) can break through the inherent limitations of imitation learning (IL) and pave the way toward superhuman intelligence in embodied agents.
OpenAI co-founder Andrej Karpathy once noted:
“There are two main types of learning in both child development and deep learning:
Imitation learning (observe and repeat—i.e., pretraining and supervised fine-tuning)
Reinforcement learning (RL). The breakthrough of AlphaGo defeating top human Go players was achieved through reinforcement learning via self-play, not by imitating professional human players.
RL-driven self-verification and reflection enables strategies that surpass human cognitive limits—these emergent abilities cannot be obtained through imitation, because the model’s cognition differs from that of its human annotators.
Humans not only don’t know how to label such problem-solving strategies—they don’t even know they exist. These strategies must be discovered during the reinforcement learning process.”
Humans not only don’t know how to label such problem-solving strategies—they don’t even know they exist. These strategies must be discovered during the reinforcement learning process.”
This perspective is already being realized in cutting-edge AI systems. In July 2024, AlphaProof became the first AI system to win a medal at the International Mathematical Olympiad. Its performance surpassed methods trained on human-centered data, thanks to its RL-based approach that emphasizes continuous interaction with formal proof systems, allowing it to explore mathematical territories beyond the reach of human theorem-proving.
Similarly, in robotics, RL is unlocking superhuman physical capabilities. Robots from Boston Dynamics and Unitree have learned, through reinforcement learning, to perform movements such as 180-degree waist rotations—far exceeding the limits of the human body.
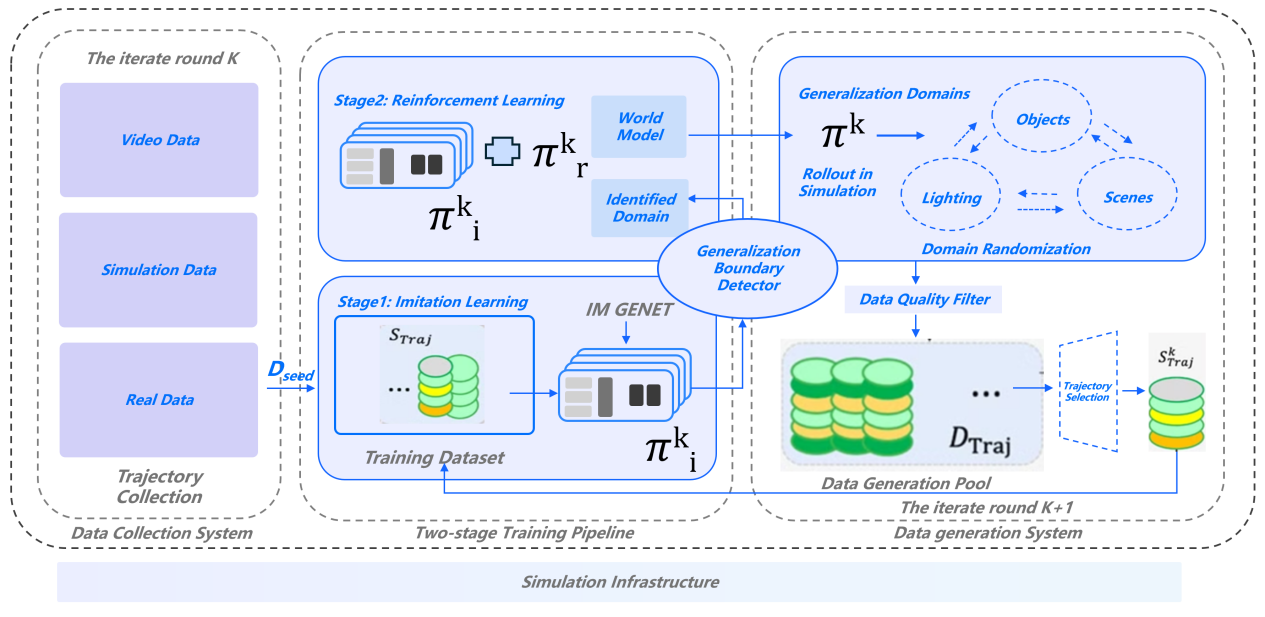
PsiBot applies reinforcement learning (RL) as a core methodology throughout its entire system stack, efficiently addressing both generalization and dexterous manipulation.
On the Fast Brain (S1) side, PsiBot has accumulated extensive Sim-to-Real RL experience, enabling large-scale skill training across diverse simulated environments. These capabilities allow PsiBot to:
· Scale up skill learning rapidly in simulation
· Minimize reliance on real-world data
· Maximize data efficiency, forming a powerful data flywheel that accelerates the transition from training to deployment
On the Slow Brain (S2) side, RL drives breakthroughs in both task success rate and Chain of Action Thought (CoAT) length. By integrating long-horizon RL with causal reasoning models, PsiBot enables:
· Longer and more coherent reasoning chains, crucial for open-ended tasks
· Higher success rates in complex environments with dynamic feedback
· The emergence of reflective, self-verifying decision strategies that evolve far beyond rule-based planning
Scenario Applications: Unlocking Commercial Value with L3 Capabilities
Scenario Applications: Unlocking Commercial Value with L3 Capabilities
General Industry: Scenarios such as incoming material bin inspection and finished goods packaging require flexible perception and precise manipulation, which L3 capabilities can fulfill with minimal reprogramming.
Retail & Logistics: Tasks like item picking, sorting, restocking, and order packing involve dynamic environments, diverse object types, and time-sensitive execution—perfectly suited to PsiBot’s CoAT-driven multimodal coordination.
2C Home Use: In the long term, L3-level embodied agents will unlock domestic service and collaboration, enabling robots to assist with household chores, object organization, and human-robot teamwork in everyday living.
At present, PsiBot has already partnered with leading enterprises across manufacturing, retail, and cross-border logistics, strategically deploying its technology in high-value commercial scenarios. The company is executing a phased rollout—from general industry, to retail and logistics, and ultimately toward consumer-facing household applications—anchored in the scalable power of its L3 embodied intelligence platform.