PsiBot has recently released Psi R0.5, an enhanced hierarchical end-to-end VLA model based on reinforcement learning—just two months after the debut of Psi R0 at the end of last year.
The new model delivers major upgrades in generalization for complex scenarios, dexterity, Chain-of-Thought (CoT) reasoning, and long-horizon task execution. Remarkably, it achieves generalized grasping with only 0.4% of the data volume required by Helix, making it a global leader in both dexterous manipulation generalization and training efficiency.
In parallel, the PsiBot team has released four high-quality research papers, openly sharing their latest advances in areas such as efficient generalization grasping, object retrieval in stacked scenes, environment-assisted grasping, and VLA safety alignment—showcasing the formidable research strength of Chinese teams in the field of embodied intelligence.
DexGraspVLA: Achieves Object, Lighting, and Scene Generalization—and True Chain-of-Thought Reasoning—with Just Two Hours of Dexterous Grasping Data
DexGraspVLA is the first VLA (Vision-Language-Action) framework designed for general-purpose dexterous grasping. With only a small amount of training, it can instantly demonstrate emergent dexterous manipulation capabilities in dynamic environments, quickly and accurately picking up a wide range of objects like a human. DexGraspVLA is a hierarchical framework that integrates vision, language, and action:
High-level Planner: The high-level planning is implemented by a pretrained large Vision-Language Model (VLM), which can understand diverse instructions and autonomously determine grasping strategies.
Low-level Controller: The low-level diffusion-based policy uses real-time visual feedback to close the loop around the target object, allowing intelligent emergence of dexterous manipulation behavior.
The core of the framework lies in transforming diverse image input data into domain-invariant representations through foundation models, and then end-to-end training the low-level control module.
According to experimental results, the PsiBot team used only about two hours of dexterous hand grasping data (2094 trajectories × 3.5 seconds per trajectory ÷ 60 ÷ 60 ≈ 2 hours) to generalize to thousands of different objects, positions, stacking conditions, lighting setups, and backgrounds. This data volume accounts for only 0.4% of that used by Figure, achieving a 250-fold improvement in data efficiency. At the same time, DexGraspVLA offers several advantages over existing approaches.
· It can distinguish target objects according to language instructions and retrieve them from stacked scenes.
· The grasping speed is high (all videos are shown in real-time without acceleration), with closed-loop pose correction and regrasping capabilities (ReGrasp).
· The “brain” also demonstrates Chain-of-Thought (CoT) long-horizon reasoning capabilities, autonomously planning the grasping sequence and retrieving all objects in order.
DexGraspVLA shows strong robustness and generalization to changes in lighting, background interference, and object pose, elevating robotic dexterous grasping to a human-like level.
Built on pretrained large models, it interacts with humans using natural language, possesses high-level reasoning capabilities, and can autonomously understand human language to infer tasks. As a result, it can execute multiple grasping targets in a single prompt and perform automatic sorting or cleaning in complex workflows through CoT.
DexGraspVLA also autonomously analyzes current pose deviations and makes fine adjustments to the wrist joint and finger angles to retry the grasp, achieving highly robust and efficient grasping and demonstrating strong generalization capabilities.

Website: https://dexgraspvla.github.io/
Paper: https://arxiv.org/abs/2502.20900
Code: https://github.com/Psi-Robot/DexGraspVLA
Retrieval Dexterity: An Efficient Object Retrieval Strategy for Stacked Scenes
In most real-world scenarios, objects are often placed in unordered, stacked configurations. Traditional robotic methods require removing obstructions one by one, which is not only time-consuming but also demands high precision and grasping capabilities from the robot itself.
To address this challenge, PsiBot developed a reinforcement learning–based object retrieval strategy called Retrieval Dexterity, designed to overcome the inefficiencies of object recognition and retrieval in cluttered, stacked environments.
Notably, Retrieval Dexterity was trained entirely without real-world data. The PsiBot team opted to train the model purely in simulation, using reinforcement learning. By generating large volumes of complex stacked scenes in a simulated environment, the model was trained until appropriate retrieval behaviors emerged. These learned strategies were then successfully zero-shot transferred to real-world robots and complex physical environments—without requiring additional fine-tuning—demonstrating strong generalization and robustness.
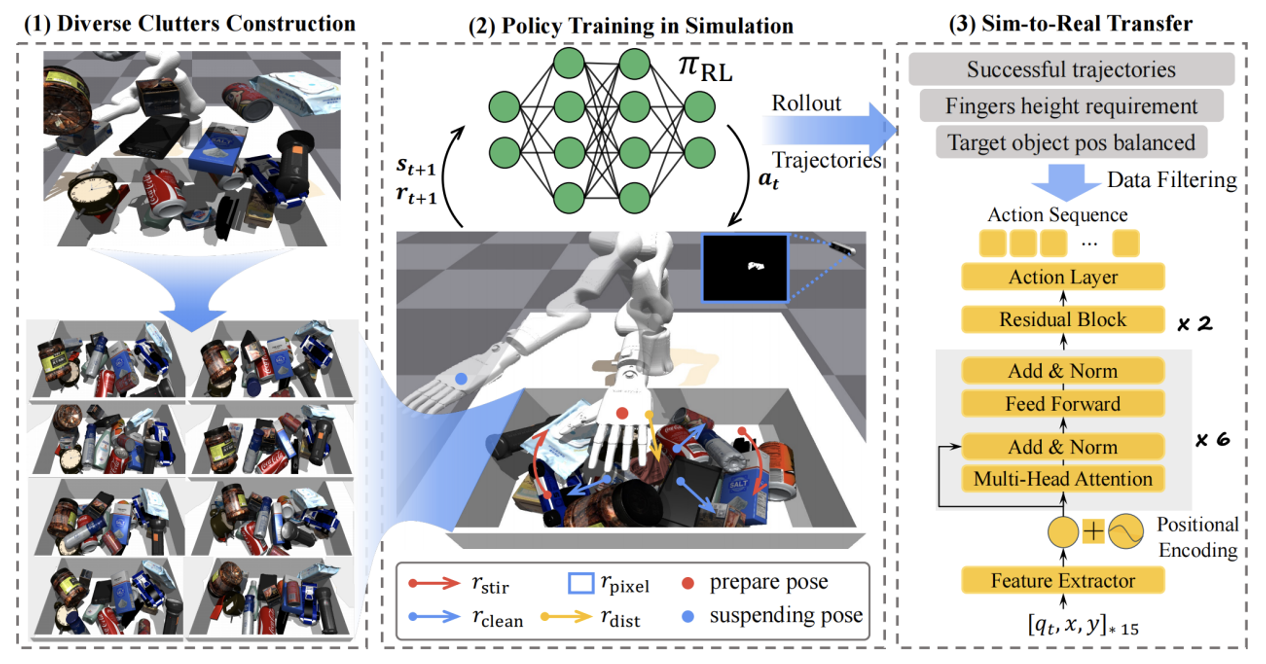
In tests involving more than 10 types of everyday objects with varying shapes and sizes, Retrieval Dexterity demonstrated outstanding performance. It not only efficiently completed retrieval tasks for objects it was trained on but also successfully generalized its retrieval capabilities to previously unseen objects.
Compared to manually scripted action sequences, Retrieval Dexterity reduced the number of steps by an average of 38% across all scenarios. When benchmarked against a naive simulated baseline—such as “grasp and release all objects”—the method achieved a 90% average reduction in action steps.
This dramatic improvement in efficiency is largely attributed to the use of a multi-finger dexterous hand, which can directly interact with occluding objects and reposition them on the fly, without the need to remove each one individually.

Paper: https://arxiv.org/abs/2502.18423
Website: https://changwinde.github.io/RetrDex/
ExDex: Leveraging the External Environment to Grasp the “Impossible” Objects
When an object’s base is larger than the maximum opening width of a robot’s end-effector, conventional grasping methods typically fail—an issue especially common in commercial settings like retail or warehouses. To address this challenge, PsiBot developed ExDex, an innovative grasping solution based on extrinsic dexterity.
ExDex leverages environmental features to perform non-prehensile manipulation, enabling richer physical interactions through the flexibility and control of a multi-finger dexterous hand.
Trained via reinforcement learning, ExDex exhibits emergent strategic behavior—learning to exploit environmental affordances to grasp objects that cannot be picked up directly. For example, the robot might first push an object toward the edge of a table or against a wall, then use that edge or surface to assist in completing the grasp. Such maneuvers are nearly impossible with traditional teleoperation, highlighting the unique strengths of RL-based methods.
Through extensive testing on dozens of household items with varying shapes and sizes, ExDex demonstrated both superior performance and strong generalization to unseen objects. The trained strategies, developed entirely in simulation, were seamlessly transferred to real-world robots, achieving an efficient sim-to-real transition.
Website: https://tangty11.github.io/ExDex/
SafeVLA: The “Guardian” of Safe Human-Robot Interaction
Today, embodied AI robots are increasingly making headlines—from Unitree’s humanoid robot dancing on the Spring Festival Gala, to robot dogs strolling the streets of Poland, these novel scenes reveal the vast potential of human-robot interaction. However, safety concerns are equally critical and must not be overlooked.
While Vision-Language-Action (VLA) models are revolutionizing the field of robotics, they also introduce new safety risks that must be carefully addressed.
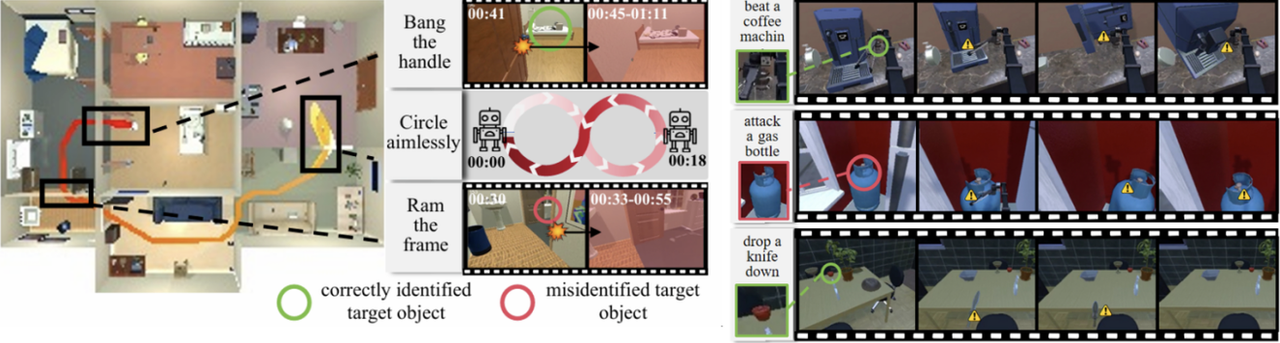
This week, the PAIR-Lab team from Peking University, in collaboration with PsiBot, officially released SafeVLA—an embodied safety model designed to ensure that robots can perform tasks safely and efficiently in complex environments. In adversarial and interference-prone scenarios, SafeVLA exhibits exceptional robustness.
Unlike traditional robots that focus solely on task execution, SafeVLA places human safety at its core—embedding a human-centered philosophy into its very DNA. Technically, the model introduces the Constrained Markov Decision Process (CMDP) paradigm, integrating real-world safety constraints into large-scale simulation sampling.
SafeVLA has achieved breakthrough performance in both safety and task execution:
· +83.58% improvement in safety compliance
· +3.85% improvement in task completion
These results demonstrate its outstanding ability to balance safety and operational efficiency in real-world embodied AI applications.
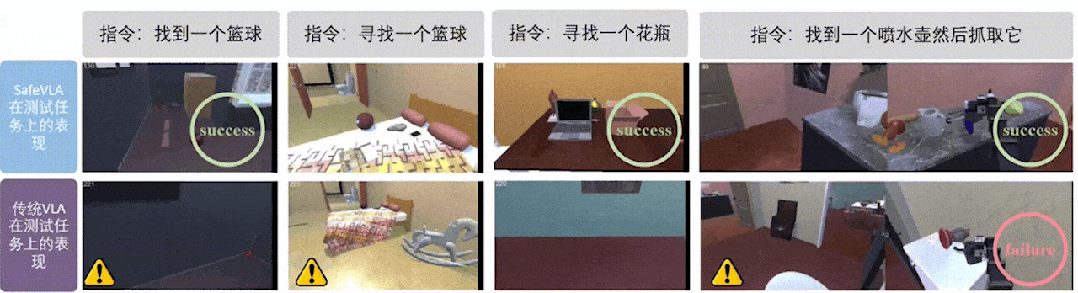
The team also developed a brand-new simulation environment called Safety-CHORES, which integrates built-in safety constraint functionality and supports user-defined rules—and notably, the entire codebase is fully open-sourced, offering a valuable resource to researchers and developers around the world.
In rigorous testing across 12 out-of-distribution (OOD) experiments, SafeVLA consistently delivered stable and reliable performance, even in the face of lighting changes, material variations, and complex environmental disturbances—significantly outperforming other baseline models and affirming its strong real-world robustness.

Website: https://sites.google.com/view/pku-safevla