Editor’s Note: In the current wave of AI advancement, the paradigm of “strong reasoning with slow deliberation” has emerged as a dominant trajectory—shaping both research priorities and investment strategies. A key frontier challenge is how to extend this paradigm to broader or even fully multimodal scenarios while ensuring alignment with human values and intent.
While previous models like Janus-Pro-7B from DeepSeek did not integrate reasoning capabilities, a domestic research team has taken a major step forward. Based on their proprietary Align-Anything framework, a joint team from Peking University and the Hong Kong University of Science and Technology (HKUST) has introduced a multimodal version of DeepSeek-R1—Align-DS-V. On certain visual understanding benchmarks, it even surpasses GPT-4o in performance. Both Align-Anything and Align-DS-V have now been open-sourced, with the team committing to long-term maintenance.
The alignment team at Peking University, led by Prof. Yaodong YANG (Assistant Professor at the Institute for Artificial Intelligence), focuses on safe human-AI interaction and value alignment. On the HKUST side, the joint effort is backed by the Hong Kong Generative AI R&D Center (HKGAI), headed by HKUST Provost and academician Professor Qiang Yang.
Building on Align-DS-V, the Peking University–PsiBot Joint Lab has already begun deeper exploration in the field of VLA (Vision-Language-Action) models. PsiBot is developing a new generation of VLA architecture in which a multimodal large model at the “brain” layer performs alignment and fine-tuning, and then outputs action tokens. These tokens are interpreted by the “cerebellum” controller, which converts them—along with other sensory inputs—into specific robotic control commands.
Both of these layers rely heavily on advanced post-training and fine-tuning techniques tailored for multimodal large models. The lab highlights that Align-DS-V’s strong multimodal reasoning is central to the brain layer of the VLA system. Their upcoming research will explore how to extend the cross-modal penetration capabilities of such models to achieve action-level penetration, ultimately enabling a highly efficient, generalizable VLA system.
The same post-training methodologies will also be applied to the cerebellar controller, further improving task success rate, generalization, and robustness—paving the way toward truly intelligent, aligned embodied agents.
Align-DS-V (Multimodal DeepSeek-R1 version): https://huggingface.co/PKU-Alignment/Align-DS-V
Align-Anything Framework: https://github.com/PKU-Alignment/align-anything
Toward Fully Multimodal Models and Alignment: The Next Leap Beyond DeepSeek-R1’s Current Milestone
Thanks to its strong reasoning and long-context processing capabilities, DeepSeek R1 has garnered significant attention since its open-source release. At AIME 2024, it achieved a score of 79.8%, slightly outperforming OpenAI’s o1-1217 model. On the MATH-500 benchmark, it reached an impressive 97.3%, matching the performance of o1-1217 and clearly surpassing other models.
In programming-related tasks, DeepSeek R1 has demonstrated expert-level competence. In competitive coding evaluations, it achieved an Elo rating of 2029 on Codeforces, outperforming 96.3% of human participants, positioning it among the top-performing code generation models to date.
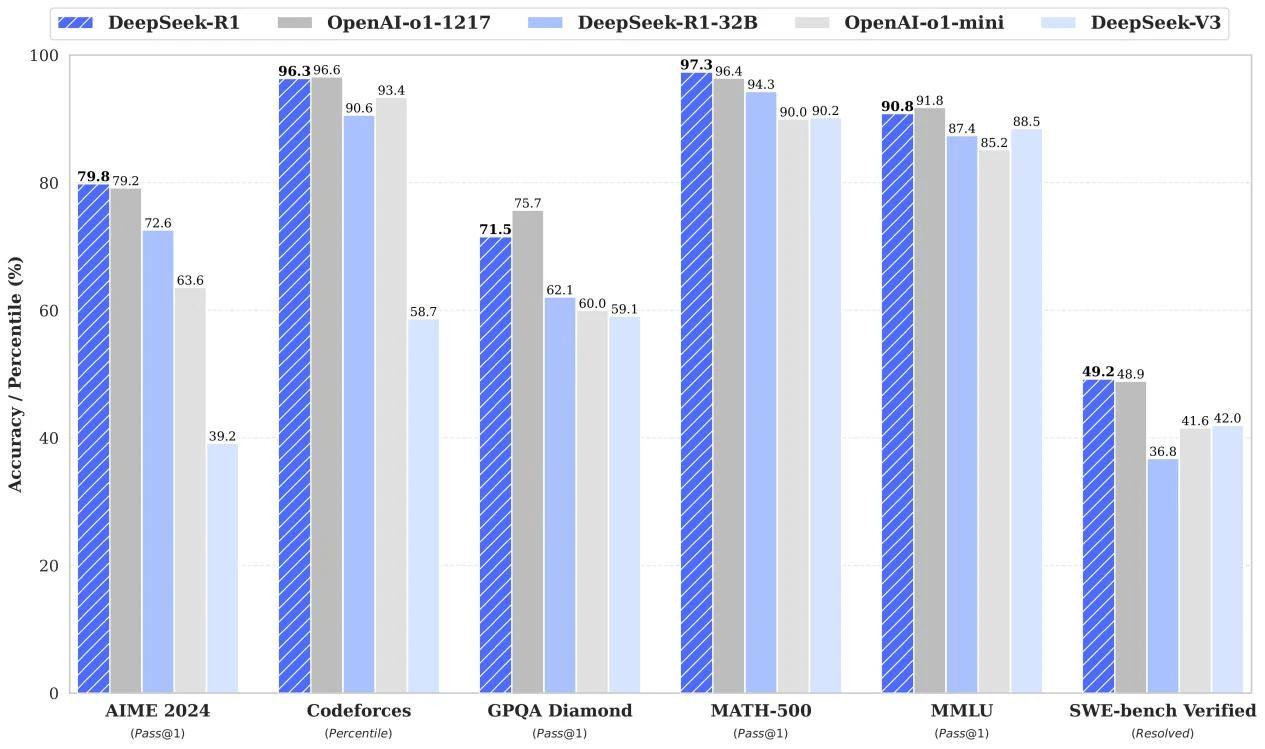
DeepSeek R1-Zero and R1 once again demonstrate the potential of reinforcement learning. R1-Zero is built entirely from a base model using reinforcement learning (RL), without relying on supervised fine-tuning (SFT) from human expert labels. During training, the model gradually shows long-context and long-chain reasoning capabilities as steps increase. As its reasoning paths extend, the model also exhibits self-correction abilities—able to identify and fix earlier mistakes.
The strong performance of DeepSeek R1-Zero and R1 in the pure-text modality leads to growing anticipation: What can we expect from DeepSeek R1’s deep reasoning capabilities in multimodal scenarios?
• Modal penetration and interaction are expected to further enhance reasoning capabilities. Humans receive information in a fully multimodal manner—different sensory channels complement each other to help us better understand and express complex concepts. This full-modality information flow is equally crucial for large models as they evolve toward general artificial intelligence. Researchers are now attempting to extend large language models into multimodal systems capable of processing and generating not just language, but also images, audio, and video—examples include GPT-4o and Chameleon.
• Full-modality expansion is likely to be the next major breakthrough for DeepSeek R1. The goal is to construct a closed-loop cognitive system of “perception–understanding–reasoning” in complex decision-making scenarios, extending the boundaries of intelligence across domains. For example, using cross-modal alignment, a model can establish semantic associations between grayscale features in CT images and medical terminology in diagnostic reports—supporting synchronized analysis of X-ray shadows and patient-reported symptoms. Moreover, this spatiotemporal reasoning capability enables autonomous driving systems to simultaneously interpret vehicle trajectories in road footage, flashing frequencies of traffic lights, and abnormal surrounding sounds—leading to more precise multidimensional risk prediction.
• Expanding strong reasoning capabilities into fully multimodal scenarios presents many challenges.
In text-based settings, many complex reasoning tasks can be supervised through rule-based rewards, which serve as proxies for human intent and preference. However, when extending from text to multimodal or fully multimodal contexts, several challenges arise:
– As the number of modalities increases, can traditional binary preferences or rule-based rewards still capture the diverse and hierarchical nature of human intent?
– When moving to fully multimodal spaces with increasingly complex interactions, what improvements are needed in RL methods?
– How can modality-specific and modality-shared information be unified in reward modeling across different input types?
Align-DS-V: The First Milestone Toward Fully Multimodal R1
Following the release of DeepSeek R1, a joint team from Peking University and the Hong Kong University of Science and Technology rapidly extended the DeepSeek R1 series into the vision-language modality within just one week, using their self-developed Align-Anything framework. The resulting model, Align-DS-V, achieved impressive performance in visual understanding tasks. Below are selected evaluation results:
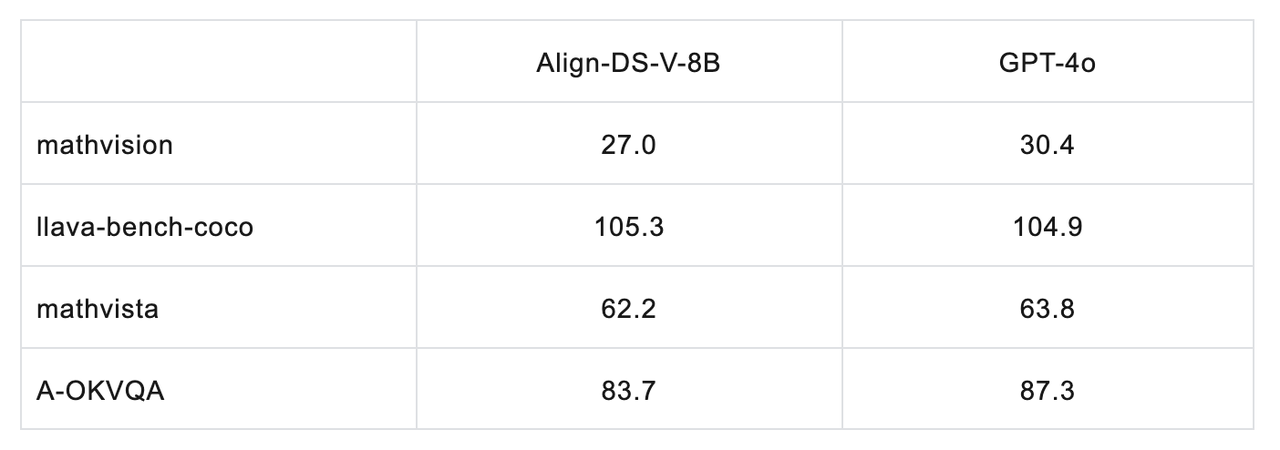
More importantly, the team also discovered that cross-modal generalization contributes to enhanced reasoning performance in the text modality.
Specifically, during the process of extending DeepSeek R1 into a fully multimodal model, the team observed that multimodal training led to improvements in the model’s performance on purely text-based tasks—including scientific problem-solving, complex reasoning, and mathematical or coding challenges.
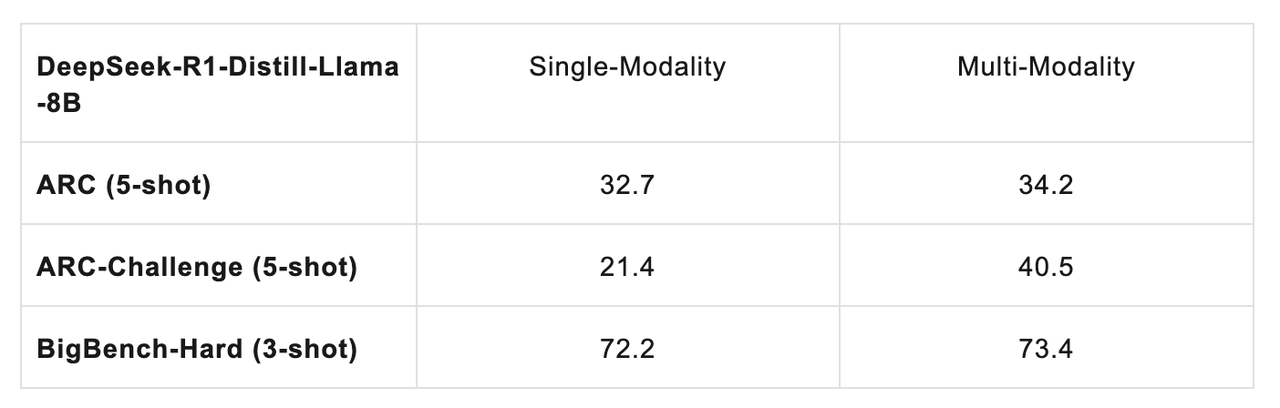
The team believes that today’s multimodal large models have developed powerful cross-modal penetration and fusion capabilities, enabling them to reason efficiently and generate coordinated outputs across multiple modalities—such as images, text, audio, and video—by leveraging both world knowledge and contextual learning.
Moreover, with continuous self-evolution driven by slow thinking and strong reasoning, these models are breaking free from the limitations of single-modality intelligence. Cross-modal penetration has deepened significantly, and through the deep integration of world knowledge, the model’s reasoning boundaries in the text modality have been notably expanded.
Align-DS-V as a Regional Value Alignment Demonstration
To validate the capabilities of fully multimodal reasoning models in domain-specific applications, the development team conducted a regional value alignment adaptation of Align-DS-V for Hong Kong. The model was fine-tuned to handle mixed-language inputs—Cantonese, English, and Mandarin—and was deeply integrated with local lifestyle scenarios such as MTR transit updates, typhoon alerts, and Octopus card payment systems.
In one example, when asked through a multimodal input which Vitasoy product (a popular local beverage) is better for fat reduction, Align-DS-V accurately identified the low-sugar original soy milk as the optimal choice. It also noted that the original soy milk is a suitable alternative for fat loss—providing practical dietary guidance tailored to everyday choices in Hong Kong.

When presented with math problems containing traditional Chinese characters in both image and text form, Align-DS-V was able to accurately integrate information across visual and textual modalities. It provided rigorous, step-by-step mathematical derivations to arrive at the correct solution—demonstrating strong reasoning capabilities and highlighting its promising potential for trustworthy applications in education and related fields.
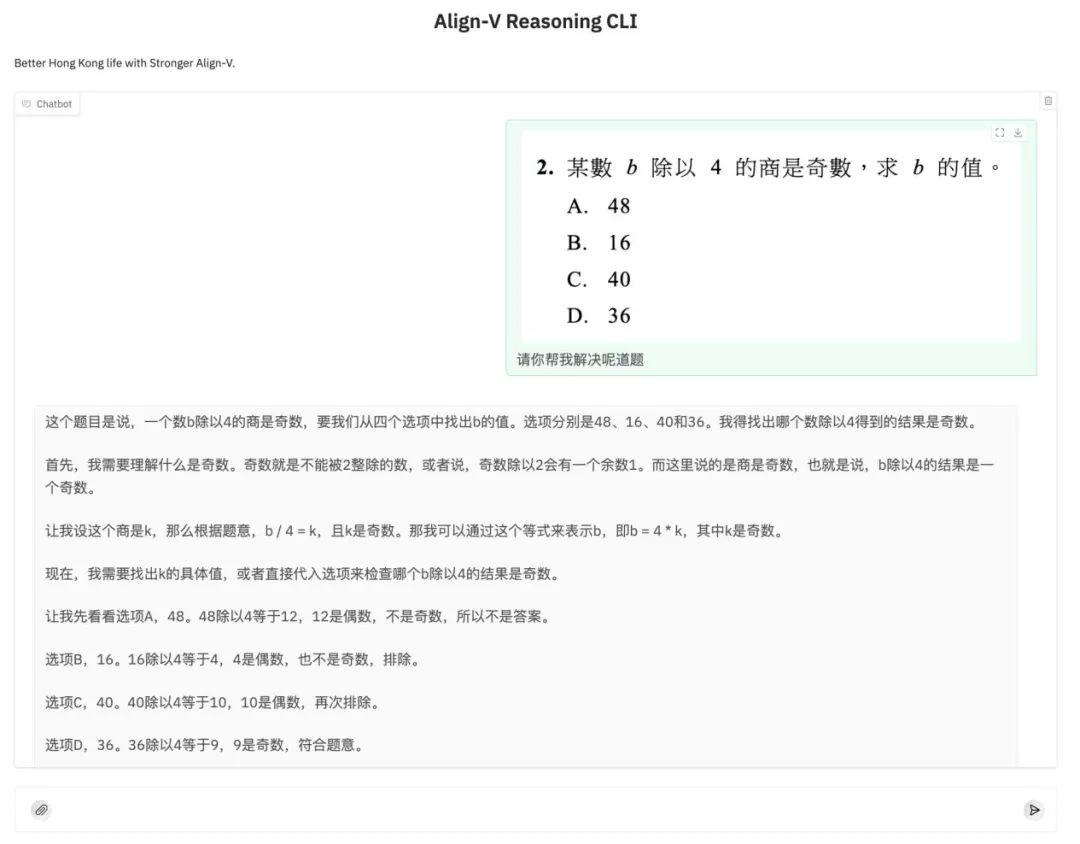
Full-Modality Alignment with Align-Anything: cross-modal generalization as the Final Piece in Unlocking Large Model Performance
The multimodal evolution of large language models (LLMs) is an unstoppable trend, and fully multimodal models—capable of accepting any modality as input and generating any modality as output—are poised to become the next major milestone. A critical and forward-looking challenge lies in aligning such models with human intent and values. However, as the number of modalities increases, so does the diversity of input-output distributions, along with a heightened risk of hallucinations—making full-modality alignment increasingly complex.
To advance research in this area, the team behind Align-Anything has contributed open-source resources across four key dimensions:
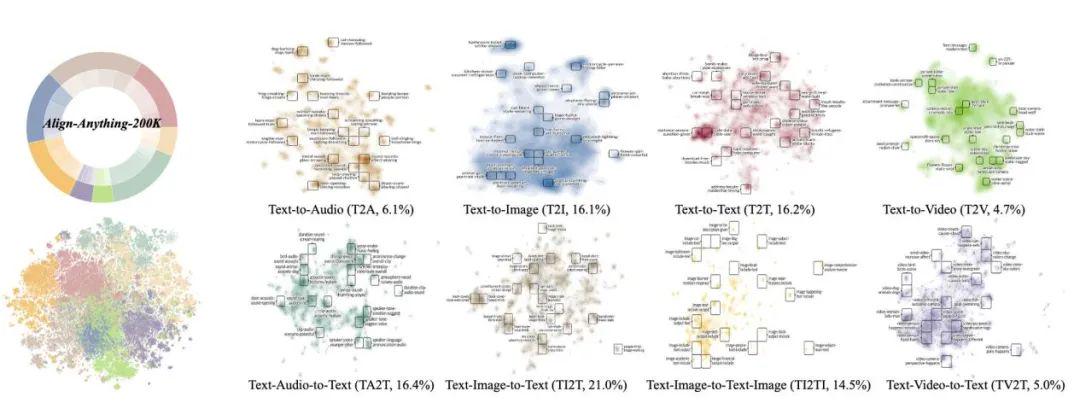
· Data: A 200K dataset containing human language feedback and binary preference annotations, covering text, image, video, and audio modalities.
· Algorithm: A synthetic data paradigm derived from language feedback that significantly improves the performance of RLHF (Reinforcement Learning from Human Feedback) post-training.
· Evaluation: New benchmarks for assessing modality coordination and modality selection in fully multimodal models.
· Codebase: A comprehensive training and evaluation framework that supports models across text, image, video, and audio modalities.
The Align-Anything framework is designed to align fully multimodal large models with human values and intent. It supports any-to-any modality mappings, including text-to-text, text-to-image, image-and-text to text, and text-to-video generation. The framework is modular, extensible, and user-friendly—allowing flexible fine-tuning for models across any derived modality from the four foundational types (text, image, audio, video).
It also provides rigorous validation of alignment algorithm correctness and demonstrates practical effectiveness in aligning fully multimodal models. The framework’s defining characteristics include:
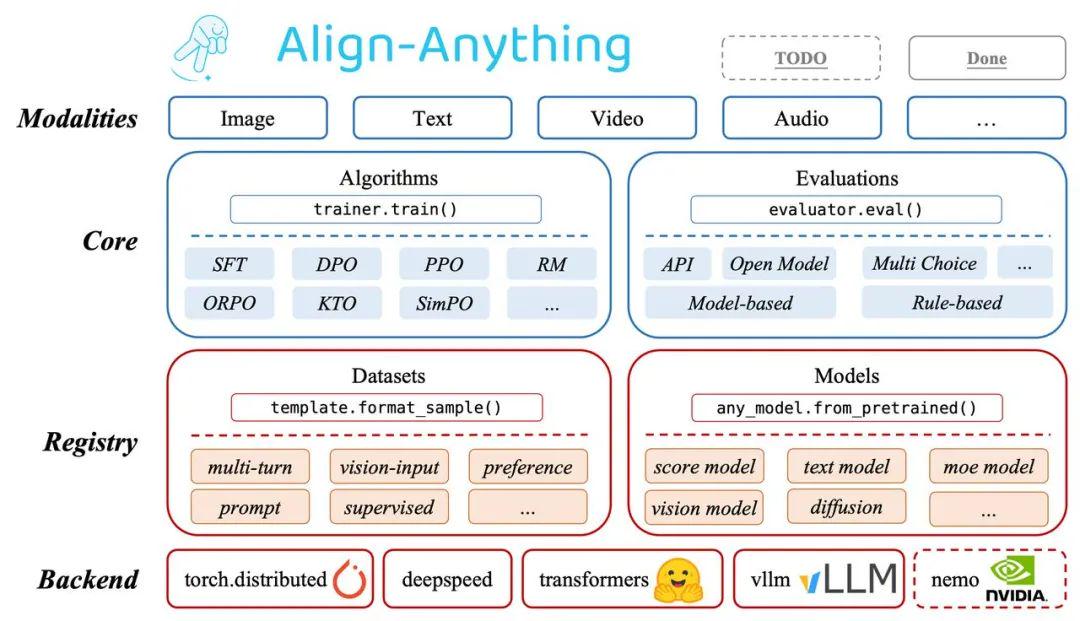
· Highly Modular Design: With abstracted support for various algorithm types and carefully designed APIs, users can easily modify and customize code for different tasks. The framework also allows advanced extensibility, such as custom model and dataset registration.
· Cross-Modality Fine-Tuning Support: Enables fine-tuning of a wide range of large models spanning multiple modalities, including LLaMA3.2, LLaVA, Chameleon, Qwen2-VL, Qwen2-Audio, Diffusion, and more—covering both generation and understanding tasks across modalities.
· Support for Diverse Alignment Algorithms: Compatible with multiple alignment methods across any modality. These include classic techniques such as SFT, DPO, and PPO, as well as newer approaches like ORPO, SimPO, and KTO.
· Comprehensive Open- and Closed-Source Evaluation: Supports over 30 multimodal evaluation benchmarks, including multimodal understanding tasks (e.g., MMBench, VideoMME) and generation metrics (e.g., FID, HPSv2).
To further empower the research community in developing fully multimodal alignment models, the team has released the first fully multimodal human preference dataset—align-anything. Unlike existing datasets that focus on a single modality and vary in quality, align-anything provides high-quality data spanning any combination of input and output modalities. It offers detailed human preference annotations along with fine-grained language feedback for critique and improvement—enabling comprehensive cross-modal evaluation and iterative enhancement.
Training Align-DS-V with Align-Anything
Inspired by LLaVA’s training approach, the team trained a projection layer (Projector) to map the output of the vision encoder into the language representation space, thereby extending DeepSeek R1’s capabilities into the visual modality. The entire training pipeline has been open-sourced in the Align-Anything library.
The process begins by building a “Text + Image → Text” architecture based on the DeepSeek R1 model series. For example, the following script illustrates the setup:
The process begins by building a “Text + Image → Text” architecture based on the DeepSeek R1 model series. For example, the following script illustrates the setup:

In the new multimodal model, the input image is first processed by a vision encoder, which extracts features and produces an intermediate representation. This representation is then passed through a projection layer (Projector) that maps it into the language embedding space, yielding a visual embedding aligned with language tokens. Simultaneously, the language instruction is processed to generate a corresponding language embedding.
Both the visual and language embeddings are then fed into the language model, which fuses the two streams of information for reasoning and ultimately generates a textual response.
Once the R1 architecture has been extended to support multimodality, the training process consists of two key steps:
Step 1: All model parameters are frozen except the Projector. The training focuses on pretraining the Projector, ensuring it learns to effectively map the visual representations produced by the vision encoder into the language space. This alignment is crucial for enabling coherent integration of visual and textual information during inference.

Step 2: The Projector and the large language model (LLM) are fine-tuned jointly. This stage aims to activate and enhance the LLM’s multimodal reasoning capabilities by allowing it to directly integrate and reason over visual and textual embeddings. Through joint optimization, the model learns to fuse modalities more effectively—enabling it to generate accurate, context-aware responses based on complex multimodal inputs.
