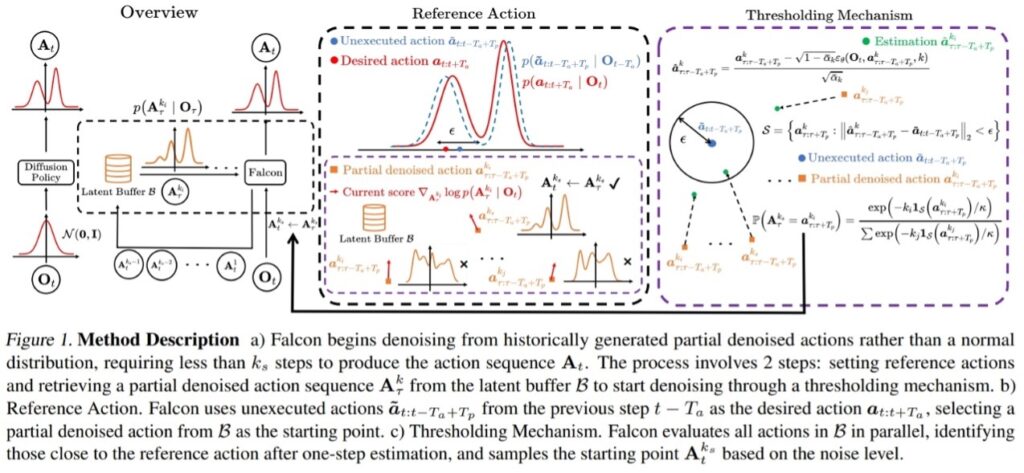
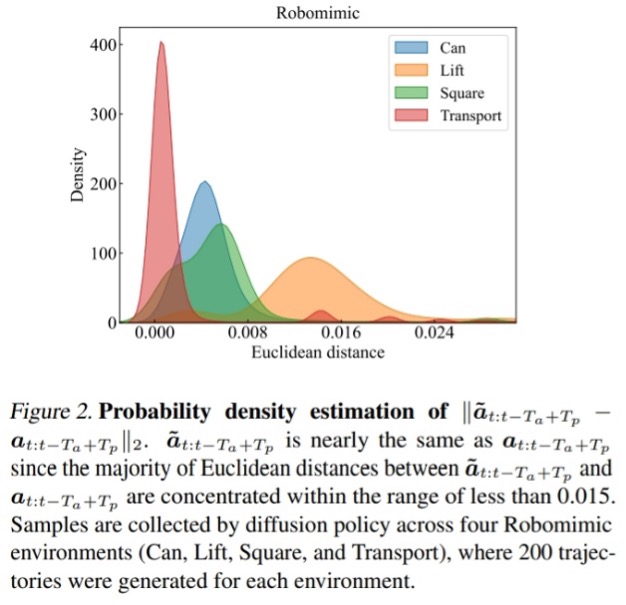
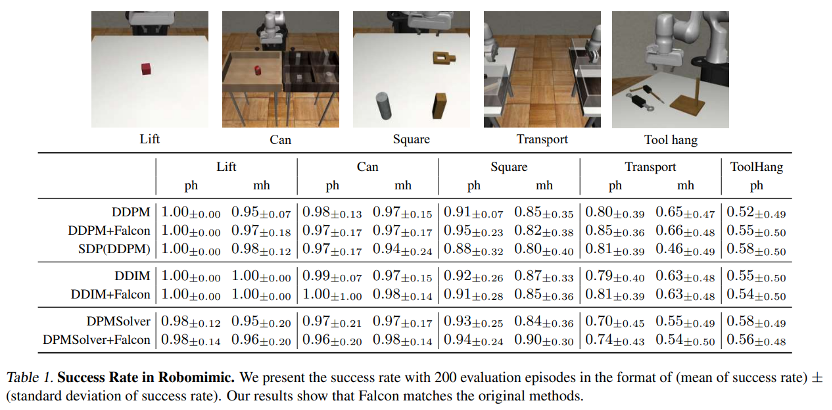
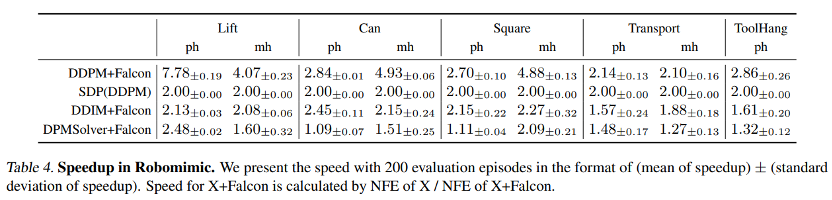
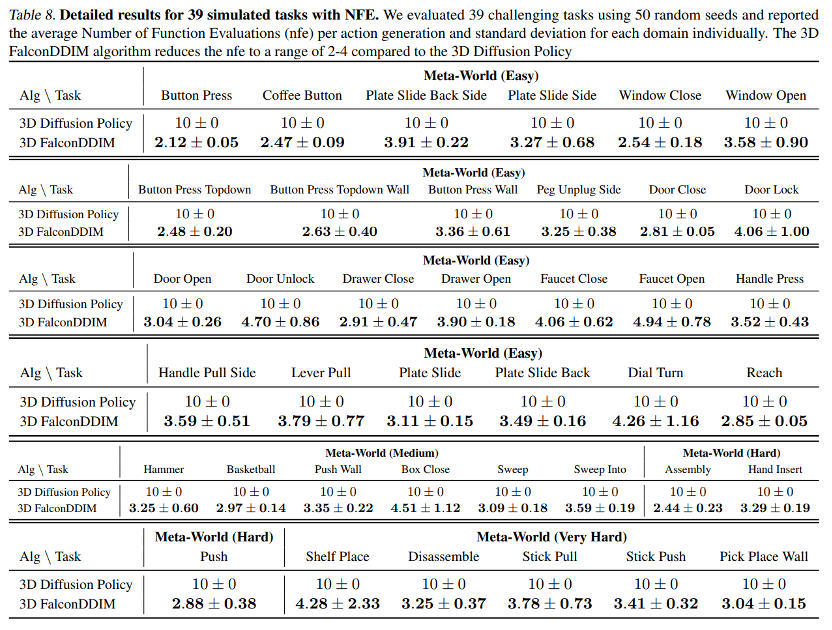
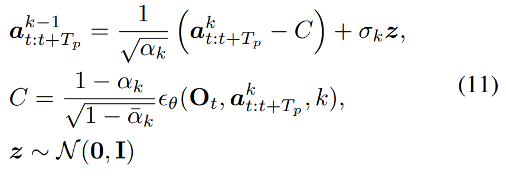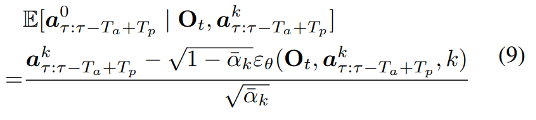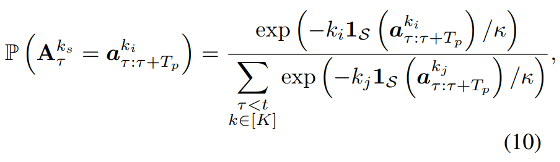参考资料:
[1] Chi, Cheng, et al. “Diffusion policy: Visuomotor policy learning via action diffusion.” The International Journal of Robotics Research (2023): 02783649241273668.
[2] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models.” Advances in neural information processing systems 33 (2020): 6840-6851.
[3] Song, Jiaming, Chenlin Meng, and Stefano Ermon. “Denoising diffusion implicit models.” arXiv preprint arXiv:2010.02502 (2020).
[4] Lu, Cheng, et al. “Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.” Advances in Neural Information Processing Systems 35 (2022): 5775-5787.
[5] Prasad, Aaditya, et al. “Consistency policy: Accelerated visuomotor policies via consistency distillation.” arXiv preprint arXiv:2405.07503 (2024).
[6] Høeg, Sigmund H., Yilun Du, and Olav Egeland. “Streaming Diffusion Policy: Fast Policy Synthesis with Variable Noise Diffusion Models.” arXiv preprint arXiv:2406.04806 (2024).
[7] Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. Vol. 1. No. 1. Cambridge: MIT press, 1998.