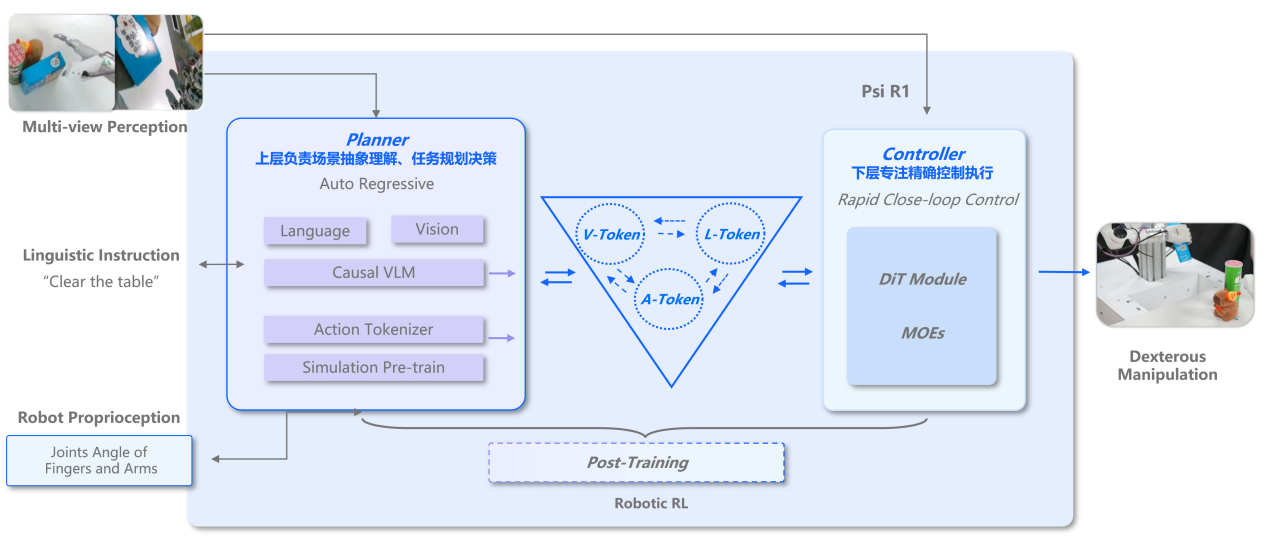
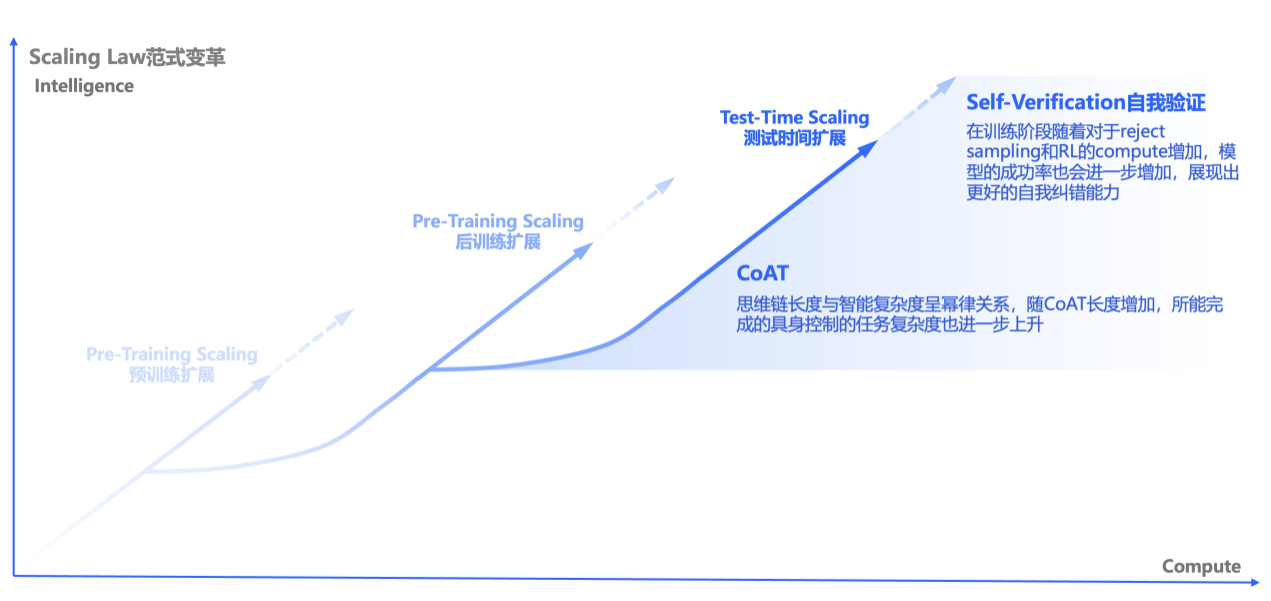
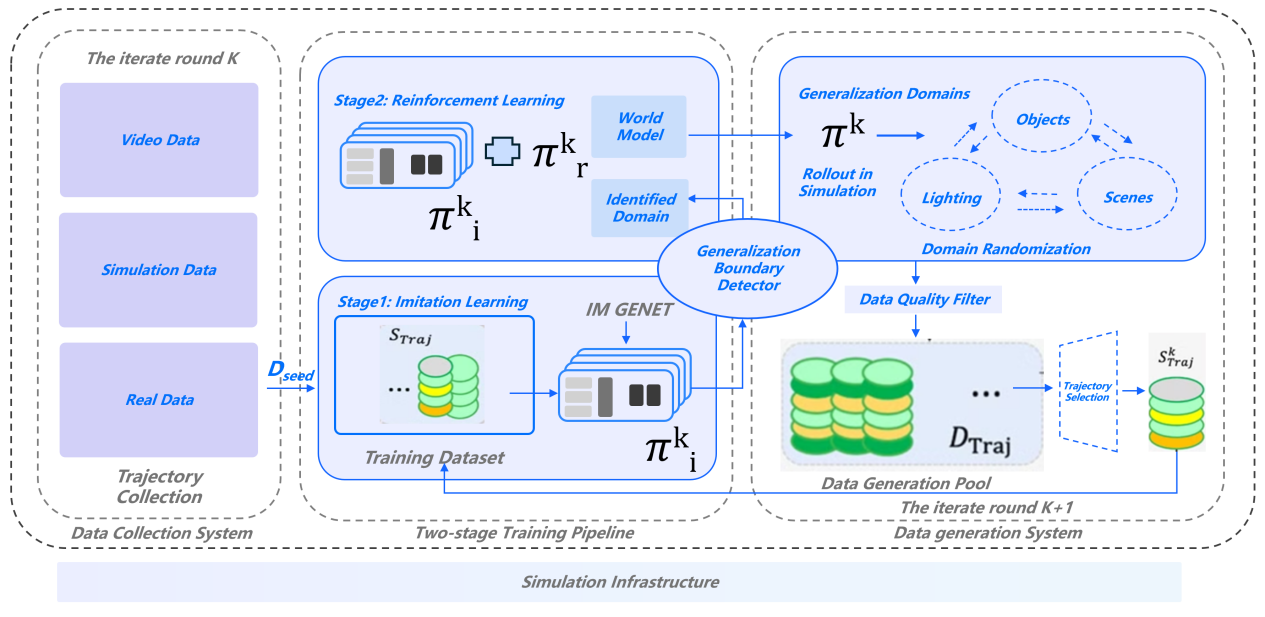
不同于Pi,Figure等「动作单向决策」机制的VLA模型(仅能完成视觉-语言层面的CoT),灵初智能的R1模型的慢脑输入包括行动Token(Action Tokenizer),构建了首个支持「动作感知-环境反馈-动态决策」全闭环的VLA模型,实现机器人操作的视觉-语言-动作多模态协同的的CoAT思维链。
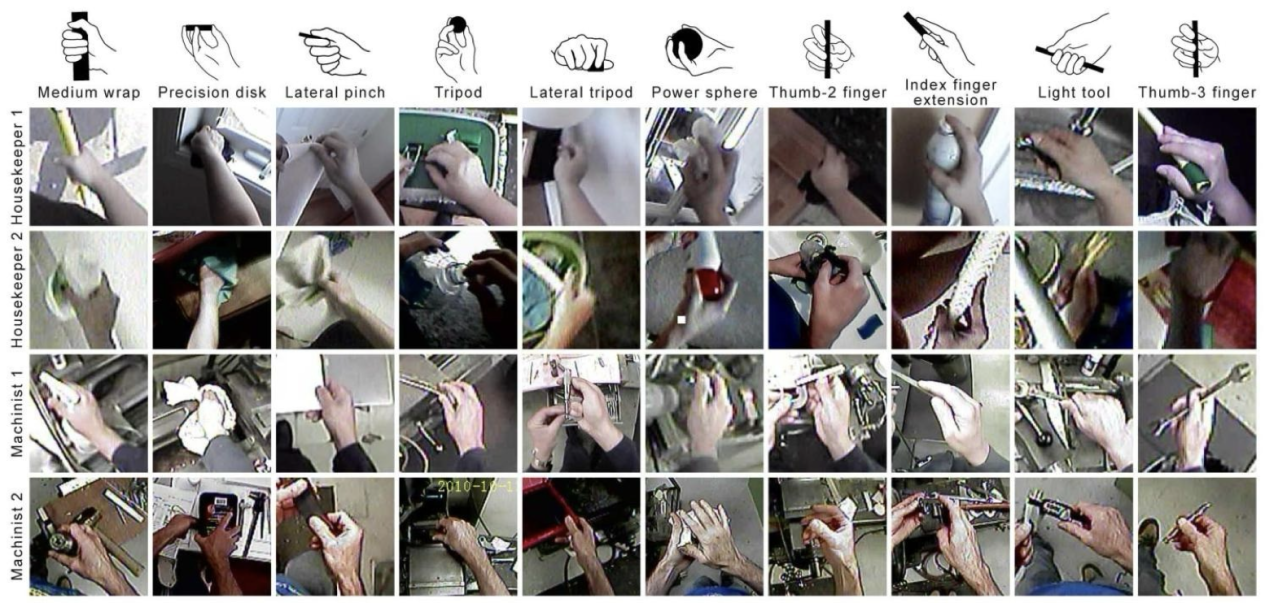
快脑S1专注于操作:灵巧操作涵盖多种形式,如物体的遮掩抓取(Object Mask-based Grasping)、物体轨迹约束的操作(Trajectory-Constrained Manipulation)如拉拉链、工作使用技能泛化(Tool-using Skills Generalization)如扫码,打电钻、高动态操作(Raw Actions Stream Execution)如抛接球等。灵初智能的RL算法支持上述所有操作类型。
慢脑S2专注于推理规划:S1的操作经过tokenize后,作为S2慢脑的输入,和语言、视觉模态融合,基于Causal VLM自回归架构,实现多模态融合的推理和任务规划。
快慢脑通过Action Tokenizer隐式连接,端到端训练,协同完成长程任务的灵巧操作。R1模型结合历史动作与当前环境状态,理解动作的长期影响,避免重复试错和动作误差积累,建立动作与环境变化的因果链,解决传统VLM因缺乏动作历史导致的「决策短视」问题。