当多模态Agent(如OpenClaw)在数字世界中展现出惊人的推理与规划能力时,具身智能的落地依然面临一道“隐形的墙”:真机强化学习极度依赖人工干预。 现有的“人在回路”(Human-in-the-Loop, HIL)模式,本质上是一种难以规模化的“作坊式”训练——一台机器人必须绑定一名人类操作员,这不仅成本高昂,更受限于人类的疲劳,并且不同操作员的干预偏好、操作习惯及决策风格存在显著差异。这种非标准化的主观干预,使得训练数据分布噪声过大,策略难以统一优化,导致真机强化学习无法像仿真环境那样实现大规模、一致性的并行迭代。
如何打破这一规模化障碍?北京大学智能学院与北大-灵初联合实验室提出了一种全新的解决方案:AGPS(Agent-guided Policy Search)。 这项工作不仅大幅提升了真机强化学习的样本效率,更关键的是,它标志着我们开始将通用的Agent能力真正应用到具身场景中,推动构建一条从数字智能通向物理智能的自动化真机强化学习训练通路。

l论文标题:Accelerating Robotic Reinforcement Learning with Agent Guidance
l论文地址:https://arxiv.org/abs/2602.11978
l项目网站:https://agps-rl.github.io/agps/
现有方法的困局:人工在线干预有效,但难以扩展
为提升真机强化学习的样本效率,现有研究通常采用 HIL 方法。当机器人偏离目标、陷入低价值探索,或长时间无法取得有效进展时,由人类操作员介入,对策略进行修正。这类方法的价值在于,它能够在训练早期直接阻断明显错误的探索路径,帮助机器人更快回到有效学习轨道,因此在一些任务中可以显著缩短训练时间。
但这种提升是建立在持续人工干预的基础上,其局限也会随着任务复杂度上升而显现。正如图1 左侧所示,随着任务复杂度增加,策略学习难度不断上升,训练过程对外部监督的需求也随之增强。然而HIL 的监督方式本质上仍接近 1:1,即一台机器人往往需要一名操作员持续在线跟进。这意味着一旦训练时间拉长或任务数量增加,人工监督很快就会成为整个系统的扩展瓶颈。
与此同时,人工干预本身也并不是稳定不变的高质量监督源。长时间参与会带来疲劳、反应延迟和操作波动,不同操作者之间的经验差异也会进一步放大干预偏差。在高精度装配或柔性物体操作等复杂任务中,这种高方差监督不仅会影响训练效率,还会削弱训练过程的稳定性。也就是说,HIL 方法虽然能够在局部上改善策略搜索,但它并没有从根本上解决真机强化学习训练中监督成本高、难标准化、难规模化的问题。
AGPS框架的提出,正是为了打破这一困局。它引入多模态智能体来取代人工监督,实现了零人工干预,推进真机强化学习训练走向自动化。
AGPS的核心创新:多模态智能体进行监督
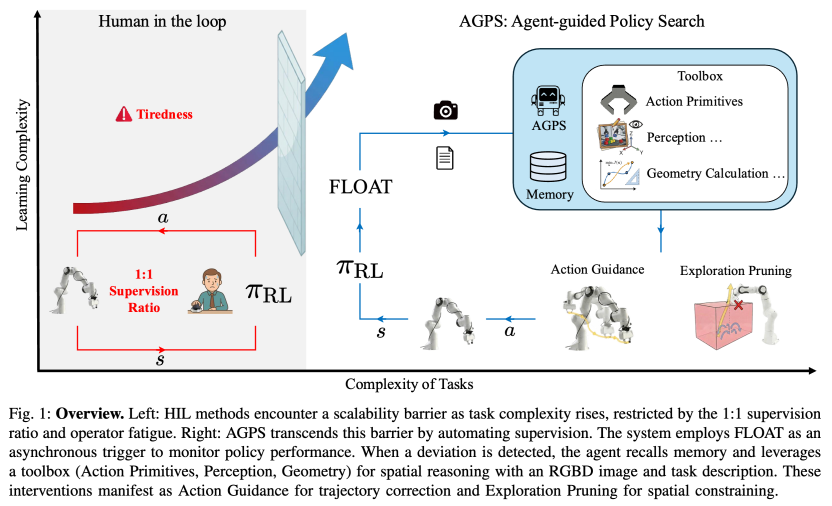
图1 论文总览:左侧是 HIL 的扩展性瓶颈,右侧是AGPS框架。
AGPS 由如下几个部件组成:在线监测模块 FLOAT,工具箱和记忆库。
FLOAT:只在“练偏了”时触发智能体
为降低多模态智能体推理延迟对训练吞吐的影响,AGPS引入在线失败检测模块FLOAT[1]。该模块首先利用预训练视觉编码器 DINOv2 ViT-B/14[2] 将当前轨迹和专家轨迹映射到隐空间中,再进行最优传输距离比较,以量化当前策略分布相对专家示范分布的偏离程度。
论文中将触发阈值设置为专家示范得分分布的95% 分位点。当偏离分数低于阈值时,系统认为当前策略仍在可接受范围内,继续执行 RL 控制;当偏离分数超过阈值时,系统暂停策略并请求智能体给出纠偏建议。
Toolbox:把语义理解落到几何上可执行的监督信号
AGPS 的关键难点在于,如何把多模态智能体的高层语义判断转化为机器人可以直接利用的几何约束。为此,论文构建了一个可执行工具箱。其一,感知模块负责从 RGBD 图像中识别任务相关关键点,并结合相机内外参将二维像素坐标反投影到世界坐标系下的三维空间。其二,动作原语库提供Lift、MoveDelta、Grasp、Release 等原子操作,使智能体能够以模块化方式拼接出纠偏轨迹。其三,记忆模块缓存历史成功轨迹中的空间约束,如有效边界框,以避免重复调用视觉语言模型。
这一设计使AGPS 与传统“看图说话”的基础模型应用方式不同。它并非仅输出自然语言描述,而是将视觉语义、空间几何和动作原语整合成可执行监督信号,从而在训练过程中真正发挥作用。
两类核心干预:动作引导与探索裁剪
在FLOAT 被触发后,AGPS 主要输出两类监督信号。第一类是动作引导(Action Guidance):当机器人已经进入失败边缘或陷入错误状态时,智能体根据当前观测、任务描述和关键点位置,识别失败模式并合成一条更合理的中间动作路径,帮助策略恢复到可学习的状态分布中。
第二类是探索裁剪(Exploration Pruning):对于真实机器人强化学习而言,很多训练时间都消耗在明显无效的探索上。AGPS 利用感知模块和几何工具构建与任务相关的三维约束盒,将策略的探索限制在更可能成功的空间范围内。相比单纯依靠奖励信号进行搜索,这种基于语义先验的空间约束能够显著缩小搜索空间。
论文进一步指出,多模态智能体在这里可以被理解为一种预训练的“语义世界模型”。它不直接负责底层闭环控制,但能够在零样本条件下指出高价值区域,并为策略提供纠偏方向。
实验结果
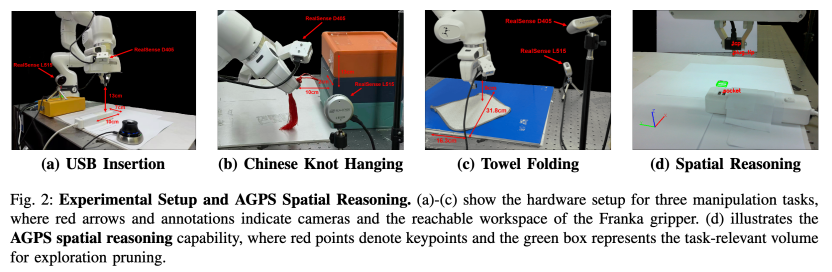
图 2 真实实验场景:USB 插入、中国结悬挂、毛巾折叠,以及 AGPS 的空间推理示意图。
论文选取了三项具有代表性的真实机器人任务:USB 插入、中国结悬挂和毛巾折叠。三者分别对应高精度刚体装配、柔性线状物体操作,以及高维柔性表面操作,覆盖了真实机器人训练中最典型、也最难的几类场景。
在评估设置上,USB 插入和中国结悬挂任务将 AGPS 与 SERL[3]、HIL-SERL[4] 等基线进行比较;毛巾折叠任务则在两阶段强化学习微调框架下,对比 HIL-ConRFT[5]。论文采用三项核心指标:成功率、达到 100% 成功率所需的收敛时间,以及训练过程中外部干预的触发频率。实验结果表明AGPS 的样本效率均显著优于人在回路的方法。
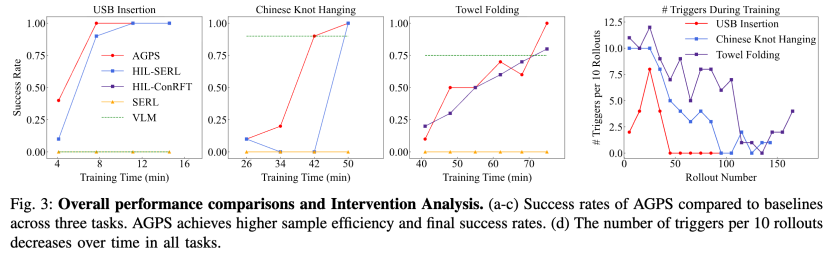
图3 主实验结果:三项任务上的成功率对比,以及训练过程中干预次数的下降趋势。
除了最终成功率,论文还分析了智能体触发次数会不会逐步下降。USB 插入任务的触发频率在早期最高,但交互了45条轨迹就降为0;挂中国结任务由于绳体动力学更复杂,干预下降得更慢,但在交互了100条轨迹左右也接近消失;折叠毛巾任务则因为状态空间更大,触发频率波动更明显,但整体仍呈下降趋势。
部分evaluation的视频,所有demo可见项目网站:https://agps-rl.github.io/agps/
论文还做了两个很重要的补充分析。其一,记忆模块可以明显提速:在USB 任务上,带记忆的 AGPS 相比不带记忆模块收敛速度提升约2 倍,因为系统可以直接复用已经验证有效的空间约束,而不必反复调用视觉语言模型(VLM)。其二,单独把 VLM 当控制器并不可靠:在 10 次独立测试中,动作引导模块本身在 USB 插入上的成功率是 0%,在中国结和毛巾折叠上分别为 90% 和 70%。
愿景:构建Agent通往具身智能的物理通路
在OpenClaw等通用Agent模型爆发的背景下,AGPS提供了一个关键的“物理适配器”。它验证了一个核心假设:无需高昂的重新训练成本,利用现有的多模态Agent 即可直接赋能物理世界的机器人学习。它描绘了一个无需人类“监工”的未来工厂——由云端 Agent 驱动大规模机器人集群进行自主迭代与进化。
结语
真机强化学习的“无人区”正在被开拓。北大团队提出的AGPS框架,不仅解决了真机强化的痛点,更关键的是,它为OpenClaw这类Agent未来在具身领域的爆发构建了一条清晰的通路。当Agent不再受限于屏幕,当强化学习不再依赖人工,具身智能的规模化时代,或许比我们想象的来得更快。
更多技术细节和实验结果请参阅原论文。
本文共同第一作者是北京大学智能学院博士生陈浩钧等,通讯作者是北京大学人工智能研究院杨耀东助理教授。
参考资料:
[1] W. Yu, J. Lv, Z. Ying, Y. Jin, C. Wen, and C. Lu, “Armada: Autonomous online failure detection and human shared control empower scalable real-world deployment and adaptation,” arXiv preprint arXiv:2510.02298, 2025.
[2] M. Oquab, T. Darcet, T. Moutakanni, H. V. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. HAZIZA, F. Massa, A. El-Nouby et al., “Dinov2: Learning robust visual features without supervision,” Transactions on Machine Learning Research.
[3] J. Luo, Z. Hu, C. Xu, Y. L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine, “Serl: A software suite for sample efficient robotic reinforcement learning,” in 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp.16961–16969.
[4] J. Luo, C. Xu, J. Wu, and S. Levine, “Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,” Science Robotics, vol. 10, no. 105, p. eads5033, 2025.
[5] Y. Chen, S. Tian, S. Liu, Y. Zhou, H. Li, and D. Zhao, “Conrft: A reinforced fine-tuning method for vla models via consistency policy,” in Proceedings of Robotics: Science and Systems, RSS 2025, Los Angeles, CA, USA, Jun 21-25, 2025.